
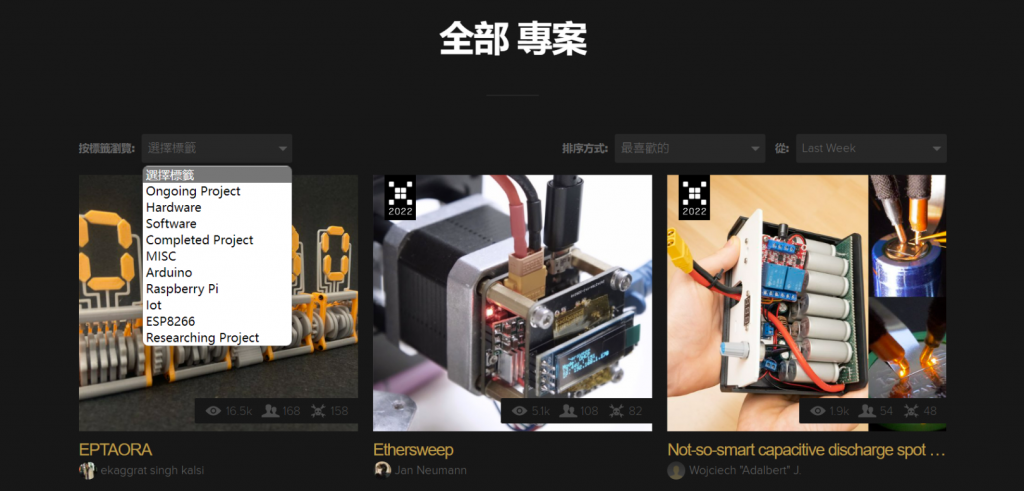
背景介绍
缘起:近来想要调研硬件领域过去几年的发展趋势,那些领域取得了较大的进步,哪些领域处于半停滞状态(发展缓慢)?Hackaday作为硬件领域最大的开源平台和社区,致力于发布世界各个角落的精彩Hack项目。因此,我们从Hackaday官网中获取开源项目,通过记录阅读量、点赞数以及学习人数等多个方面的数据,后续结合智能算法实现发展趋势的预测。
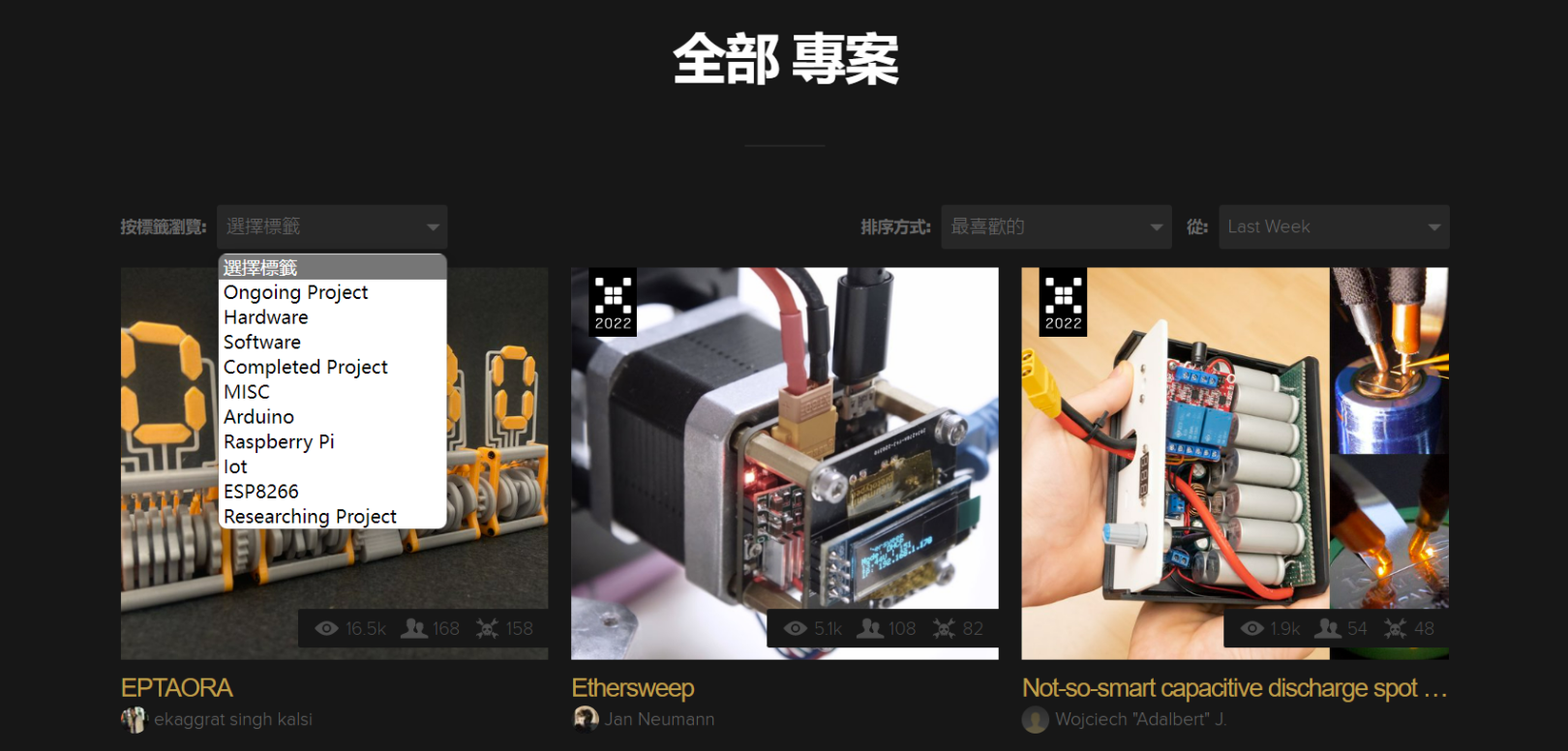
图1 Hackaday开源项目
研究目标
项目执行过程中主要存在:1.数据量大;2.网页卡顿问题。因此,为了提高项目推进的速度,我们采用爬虫程序,实现数据的提取及存储。其中,系统采用私有化部署,原生微服务架构,能够极为方便的对系统进行扩展,主要包含的功能模块有:1.数据抓取模块;2.数据存储模块;3.数据分析与数据挖掘模块(异常报警);4.数据可视化模块。
项目执行过程中所用的工具有:1.pycharm集成开发环境;2.PostgreSQL数据库;
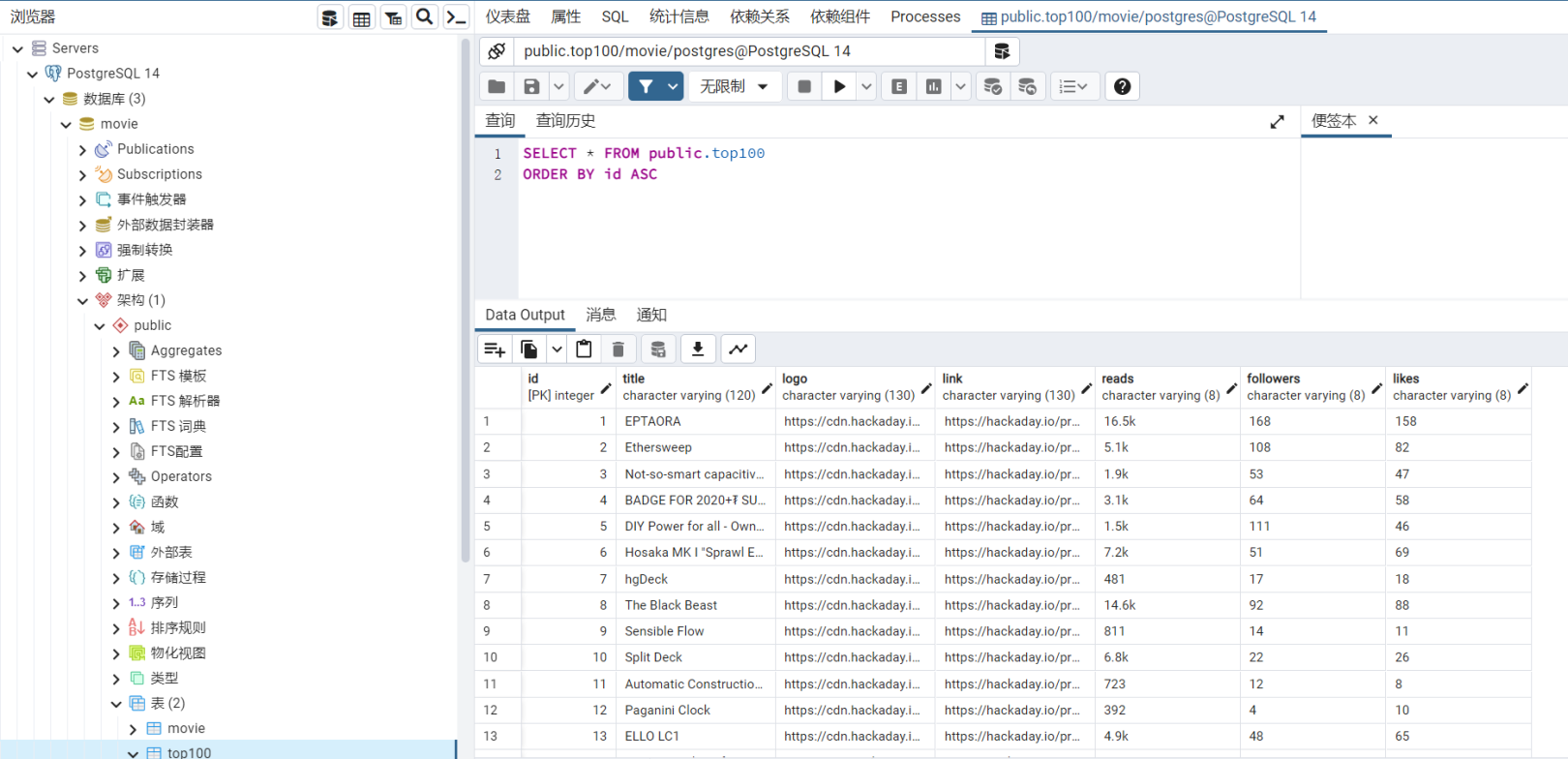
程序源代码
将互联网看成为一张蜘蛛网,那么网络爬虫(Web Spider)就相当于网上的蜘蛛。网络爬虫作为一种很好的数据采集手段,能按照一定规则对互联网上的数据、脚本等信息进行抓取,具体所用的代码如下图所示:
import re #正则表达式,进行文字匹配
import urllib.request,urllib.error #制定URL
import psycopg2
from bs4 import BeautifulSoup
from lxml import etree
#项目链接
findLink=re.compile(r'<a class="item-link" href="(.*?)"')#?表示.*出现0次到1次
#展示效果图
findImgSrc1=re.compile(r'<div class="project-item-cover" style="background-image: url(.*?)"',re.S)#?表示.*出现0次到1次
#<div class="project-item-cover" style="background-image: url(https://cdn.hackaday.io/images/resize/600x600/2120071665219410447.JPG)"
# title="EPTAORA by ekaggrat singh kalsi">
findImgSrc2=re.compile(r'<div class="project-item-cover lazy" data-src="(.*?)"',re.S)#?表示.*出现0次到1次
#<div class="project-item-cover lazy" data-src="https://cdn.hackaday.io/images/resize/600x600/8538871664887539744.JPG"
#title="DIY Power for all - OwnTech by Jean Alinei">
#<a href="https://movie.douban.com/subject/1291546/"> 源码中的样子
#findImgSrc=re.compile(r'<img.*src="(.*?)"',re.S)#re.S忽略换行符
#项目名称
findTiTle=re.compile(r'<a href=.*>(.*?)</a>')
#<a href="/project/187684-eptaora" title="EPTAORA">EPTAORA</a>
def main():
baseurl = "https://hackaday.io/projects?page="
#爬取网页
deleteOperate();
#init_db()
datalist=getData(baseurl)
print(datalist)
def getData(baseurl):#爬取网页
datalist=[]
id=0
for i in range(0,8):#调用获取网页函数10次
url=baseurl+str((i+1)*1)
html=askURL(url)#保存获取到的网页源码
#逐一解析
soup= BeautifulSoup(html, "html.parser")
for item in soup.find_all("div","project-item"): #查找符合要求的字符串,形成列表
data=[] #
item=str(item)
link=re.findall(findLink,item)[0]#re库通过正则表达式查找指定字符串的第一个符合条件的
links='https://hackaday.io'+link
data.append(links)
j=id%21+1
if (j<6):
imgSrc = re.findall(findImgSrc1, item)[0]
imgSrc=imgSrc.replace("(", "").replace(")", "")
data.append(imgSrc)
else:
imgSrc = re.findall(findImgSrc2, item)[0]
data.append(imgSrc)
titles=re.findall(findTiTle,item)[0]#片名
titles1 = titles.replace("'", "")
data.append(titles1) #
Selector = etree.HTML(item)
readings=Selector.xpath("//span/text()")
readingpeople= ",".join(readings)
readings = readingpeople.replace("\n", "").replace(" ", "").replace("ProjectOwner,Contributor", "")
readings1=readings.split(',')
readings2=list(filter(None, readings1))
if len(readings2)==3:
peopledata=readings2
else:
peopledata=['null','null','null']
datalist.append(data)#把处理好的信息放入datalist
id = id + 1
saveData(data,id,peopledata)
return datalist
def askURL(url):#得到指定的一个网页内容
#模拟浏览器头部信息
'''
'''#注意UserAgent的格式与网页上的格式,否则报错418
head = { # 用户代理,表示告诉服务器我们是什么类型的机器、浏览器(告诉浏览器我们可以接收什么水平的信息)
"User-Agent": "Mozilla / 5.0(Windows NT 10.0;WOW64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 72.0.3626.121Safari / 537.36"
}
request=urllib.request.Request(url,headers=head)
html=""
try:
response=urllib.request.urlopen(request)
html=response.read().decode("utf-8")
#print(html)
except urllib.error.URLError as e:
if hasattr(e,"code"):
print(e.code)
if hasattr(e,"reason"):
print(e.reason)
return html
def saveData(datalist,id,peopledata):
index = []
connection = psycopg2.connect(database="movie", user="postgres", password="postgres", host="127.0.0.1",
port="5432") # 连接数据库
cursor = connection.cursor() # 获取游标
cursor.execute("INSERT INTO Top100 (id, title, logo, link, reads, followers, likes) values"
" ('{0}','{1}','{2}','{3}','{4}','{5}','{6}')".format(id, datalist[2],
datalist[1], datalist[0],peopledata[0],peopledata[1],peopledata[2]))
connection.commit()
cursor.close()
connection.close()
def init_db():
sql = '''
create table Top100
(
id integer primary key not null,
title varchar(120) not null,
logo varchar(130) not null,
link varchar(130) not null,
reads varchar(8) not null,
followers varchar(8) not null,
likes varchar(8) not null
)
'''
connection = psycopg2.connect(database="movie", user="postgres", password="postgres", host="127.0.0.1",
port="5432") # 连接数据库
cursor = connection.cursor() # 获取游标
cursor.execute(sql)
connection.commit()
connection.close()
def deleteOperate():
connection = psycopg2.connect(database="movie", user="postgres", password="postgres", host="127.0.0.1",
port="5432") # 连接数据库
cursor = connection.cursor() # 获取游标
cursor.execute("select id,title,logo,link,reads,followers,likes from Top100")
rows = cursor.fetchall()
for row in rows:
print('id=', row[0], ',title=', row[1], ',logo', row[2], ',link=', row[3], ',reads', row[4], ',followers', row[5], ',likes', row[6], '\n')
print('begin delete')
cursor.execute("delete from Top100 where id<500")
connection.commit()
print('end delete')
print("Total number of rows deleted :", cursor.rowcount)
connection.close()
if __name__=="__main__":
main()

